2、分析CSV
Pymatgen (Python Materials Genomics) 是一个用于材料分析的强大的开源 Python 库。元素 (Element)、位点 (Site)、分子 (Molecule) 和结构 (Structure) 都可以使用Pymatgen的类进行表示。能够进行相图生成、Pourbaix 图生成、扩散分析、反应分析等,以及态密度和能带结构的分析。
在上面的CSV文件中,我们得到了以下的数据:
material_idformulaenergy_above_hullformation_energyband_gap- density
- volume
- nsites
然而,可以观察到formula的属性是字符串String类型,传统方法统计钙钛矿每一个位点的成分元素,只能通过字符串遍历和比对的方式进行统计,而pymatgen提供了一个很好的方法化解了这一难点。
#导入核心包
from pymatgen.core import Composition
#定义方法
defparse_formula(formula):
comp=Composition(formula)
return comp.get_el_amt_dict()
当传入参数“CsPbI3”后,控制台输出了以下内容:
{'Cs':1.0, 'Pb':1.0, 'I':3.0}
可以看到,String类型的化学式被精确的拆分出来每一个元素,这就能很好的统计数据库中,所有的结构的元素成分特征。
下面,统计每一种元素出现的频率,使用元素周期表样式,绘制热力图。
df = pd.read_csv(FILE_NAME)
formulas = df["formula"]
comps = []
for f in formulas:
comps.append(parse_formula(f))
这里,comps = [] 有了每一条化学式的所有元素的频率,现在,统计所有化学式的所有元素的频率。
defbuild_element_counts(comps):
#定义一个KV键值对字典{}
element_counts = defaultdict(int)
'''
如果单独使用 element_counts={},这里是空字典,添加键值时,如第一个元素Mg,dict找不到"Mg"键,会报错。
这里需要先创建键,再填充。
element_counts={}
for comp in comps:
for el,amt in comp.items():
element_counts[el]=element_counts.get(el,0.0)+amt
'''
for comp in comps:
'''
comp.items()从comps[{},{},{}]获取comp{}
每一个comp字典{'Cs': 1.0, 'Pb': 1.0, 'I': 3.0}
'''
for el, amt in comp.items():
element_counts[el] += amt
returndict(element_counts)
在上面的函数中,通过创建字典,遍历每一条化学式的元素字典的值,返回{元素,出现次数}字典。
下面,绘制元素周期表样式的热力图。
import matplotlib.pyplot as plt
#渐变色包
from matplotlib.colors import LinearSegmentedColormap
import matplotlib.patches as patches
import matplotlib.colors as mcolors
from pymatgen.core.periodic_table import Element
import numpy as np
defget_element_pos(z):
"""根据原子序数返回在周期表中的行列坐标 (0-indexed)"""
# 镧系: Z = 57 ~ 71 -> 放到独立区域第8行 (索引8)
if57 <= z <= 71:
return8, (z - 57) + 2
# 锕系: Z = 89 ~ 103 -> 放到独立区域第9行 (索引9)
elif89 <= z <= 103:
return9, (z - 89) + 2
# 其他元素使用 pymatgen 内置的行和族
e = Element.from_Z(z)
return e.row - 1, e.group - 1
'''
element_counts={'Mg': 399.0, 'U': 123.0, 'O': 42528.0, 'Pr': 520.0, 'Cu': 512.0, 'K': 1708.0, 'Li': 490.0, 'Nd': 580.0,
'I': 1206.0, 'Ga': 306.0, 'Ag': 381.0, 'Cl': 3101.0, 'Bi': 737.0, 'Mo': 269.0, 'Ba': 2991.0, 'Na': 1240.0, 'Ce': 331.0,
'La': 2319.0, 'Ni': 359.0, 'Cs': 1238.0, 'Rb': 1273.0, 'Sb': 587.0, 'Sr': 3199.0, 'In': 502.0, 'Re': 91.0, 'Ta': 399.0,
'Ti': 1437.0, 'Al': 298.0, 'Pb': 338.0, 'Sm': 385.0, 'Hf': 262.0, 'Sn': 371.0, 'Pd': 156.0, 'F': 4214.0, 'Ca': 2110.0,
'Cr': 701.0, 'Eu': 782.0, 'Ru': 405.0, 'Ir': 248.0, 'Tb': 296.0, 'Tl': 336.0, 'Y': 350.0, 'Pt': 84.0, 'Nb': 716.0,
'Mn': 2435.0, 'V': 501.0, 'Fe': 1028.0, 'As': 125.0, 'N': 281.0, 'Co': 779.0, 'Au': 178.0, 'S': 907.0, 'Zn': 162.0,
'W': 563.0, 'Dy': 225.0, 'Ho': 130.0, 'B': 87.0, 'Zr': 327.0, 'Tm': 144.0, 'C': 182.0, 'Be': 54.0, 'Hg': 135.0,
'Gd': 185.0, 'Br': 1802.0, 'Cd': 93.0, 'Sc': 227.0, 'Se': 341.0, 'Np': 20.0, 'Ac': 18.0, 'Er': 131.0, 'Rh': 223.0,
'Ge': 83.0, 'H': 232.0, 'Yb': 101.0, 'Lu': 129.0, 'Th': 23.0, 'P': 25.0, 'Si': 55.0, 'Te': 111.0, 'Tc': 29.0, 'Os': 66.0,
'Pa': 31.0, 'Pm': 9.0, 'Pu': 35.0}
'''
#主调用
defelements_analysis(element_counts):
counts_dict = {}
'''
counts_dict ={1: 232.0, ..., 118: 0}
'''
for z inrange(1, 119):
#返回整个元素表的元素
el = Element.from_Z(z).symbol
counts_dict[z] = element_counts.get(el, 0)
# 2. 对数缩放,使用 log1p=ln(1 + x)平滑极大值与极小值的差异
'''
log_counts={}
for z,cnt in counts_dict.items():
log_counts[z]=np.log1p(cnt)
K:V<=>z:np.log1p(cnt)
'''
log_counts = {z: np.log1p(cnt) for z, cnt in counts_dict.items()}
#log_counts非空,取最大的值->max_log
max_log = max(log_counts.values()) if log_counts else1
if max_log == 0:
max_log = 1# 防止全为0时发生除0报错
# 3. 设置自定义渐变色 (最浅色对应0次,最深色对应最大次数)
cmap = LinearSegmentedColormap.from_list(
"custom_blue",
["#d4e9f7", "#0a2639"]
)
# 归一化映射器
#为什么需要归一化?log1p取值范围是[0,+∞),图像绘制需要归一化
norm = mcolors.Normalize(vmin=0, vmax=max_log)
#输出16行,9列
fig, ax = plt.subplots(figsize=(16, 9))
# 4. 遍历所有 1-118 号元素进行绘制
for z inrange(1, 119):
el_symbol = Element.from_Z(z).symbol
count = counts_dict[z]
log_val = log_counts[z]
row, col = get_element_pos(z)
print(el_symbol,count,log_val,row,col)
# 调整 Y 轴坐标,让 row=0 出现在最上方
y = 9 - row
x = col
# 获取映射颜色 (如果 count 是 0, log_val 是 0, 会拿到最浅的 "#d4e9f7")
color = cmap(norm(log_val))
# 画元素的方块
rect = patches.Rectangle(
(x, y), 1, 1,
linewidth=1, edgecolor="white", facecolor=color
)
ax.add_patch(rect)
# 动态字体颜色:深色背景用白字,浅色背景用黑字,保证可读性
text_color = "white"if log_val > max_log * 0.5else"black"
# 标注元素符号
ax.text(
x + 0.5, y + 0.6,
el_symbol,
ha="center", va="center",
fontsize=11, fontweight="bold", color=text_color
)
# 标注出现次数 (处理带小数的配比数,如 0.5 就不转为整型)
display_count = int(count) if count == int(count) elseround(count, 2)
ax.text(
x + 0.5, y + 0.3,
str(display_count),
ha="center", va="center",
fontsize=9, color=text_color
)
# 5. 补充指示符:在主体表中镧系和锕系留出的空位画个占位符
# 镧系位置: 6周期3族 -> row 5, col 2
# 锕系位置: 7周期3族 -> row 6, col 2
ax.text(2.5, 9 - 5 + 0.5, "*", ha="center", va="center", fontsize=16)
ax.text(2.5, 9 - 6 + 0.5, "**", ha="center", va="center", fontsize=16)
ax.text(1.5, 9 - 8 + 0.5, "* Ln", ha="center", va="center", fontsize=12)
ax.text(1.5, 9 - 9 + 0.5, "** An", ha="center", va="center", fontsize=12)
# 6. 图表收尾设置
ax.set_xlim(0, 18)
ax.set_ylim(0, 10)
ax.axis("off")
# 添加 Colorbar
sm = plt.cm.ScalarMappable(cmap=cmap, norm=norm)
sm.set_array([])
cbar = plt.colorbar(sm, ax=ax, fraction=0.02, pad=0.04)
cbar.set_label("log(1 + Count)", fontsize=12)
cbar.outline.set_visible(False)
plt.title("Periodic Table of Elements Frequency (All 118 Elements)", fontsize=18, fontweight="bold", pad=20)
plt.tight_layout()
plt.savefig("heatmap.png")
运行后,导出热力图:
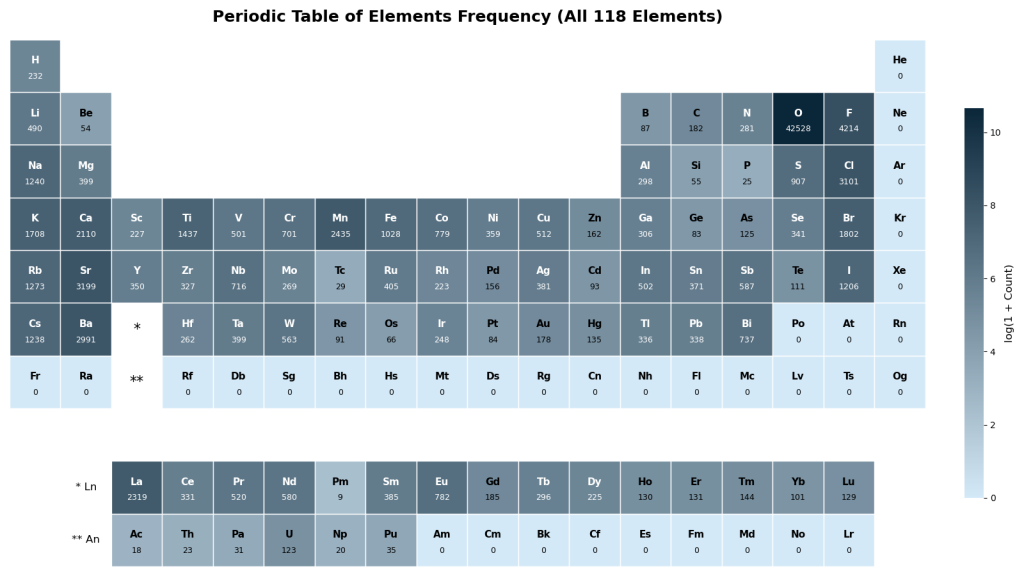
可以发现: 出现频率最高的元素是氧,这意味着,这些结构中大部分都是氧化物钙钛矿ABO3构型。同时,如 Sr (3199)、Ba (2991)、Ca (2110),以及 La (2319)都是极高频次的元素,这表明,在这些结构中,它们占据 氧化物钙钛矿半径较大的 A 位。而 Ti (1437)、Mn (2435)、Fe (1028)** 等过渡金属则通常占据 B 位。这构成了如BaTiO3、SrTiO3、LaMnO3 等经典陶瓷和铁磁、压电材料。
类似的,卤族元素F,Cl,Br,I也有很高的占比,这些材料主要是钙钛矿光伏类型的材料,如经典结构CsPbI3,他们出现的频率是Cs (1238)以及Pb (338)和 I(1206)。
除此以外,所有的稀有气体元素(He, Ne, Ar等)以及大部分锕系和超重人工放射性元素频次均为 0,这张图展示了现有的 MP 数据库的先验概率分布。
高频元素区域是模型容易“插值”并生成稳定结构的舒适区,而处于低频次或0频次的元素包含着未被充分探索的材料设计空间。
上一篇:学习笔记|从0开始学习机器学习·实践|第一节 建立材料数据库01
下一篇:待更新